A high-performance Large Language Model inference engine written in pure Object Pascal.
Overview
PasLLM is a native Pascal implementation for running LLMs locally with optimized quantization and inference capabilities. It supports multiple model architectures and features advanced 4-bit quantization formats for efficient model deployment.
It is currently CPU-only, with no GPU acceleration. GPU acceleration will be added in the future using my PasVulkan framework, but this will take time and effort. Until at least Q2 2026, I’m focusing on other professional projects, so please be patient. The same applies to support for multi-modal models, models with newer architectures (Mamba, etc.) and so on.
Features
- Pure Object Pascal – No Python or external dependencies for inference
- Cross-Platform – Compatible with Delphi ≥11.2 and FreePascal ≥3.3.1
- Multiple Architectures – Support for Llama, Qwen, Phi, Gemma, Mixtral, and more
- Advanced Quantization – Custom Q4*NL formats (Q40NL, Q41NL, Q42NL, Q43NL) with superior tail reconstruction
- Optimized Performance – Native Pascal implementation with platform-specific optimizations
- CLI and GUI – Both command-line interface and visual applications (FMX, VCL, LCL)
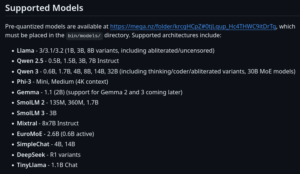
Supported Models
Pre-quantized models are available at https://mega.nz/folder/krcgHCpZ#0tjLqup_Hc4THWC9itDrTg, which must be placed in the bin/models/ directory. Supported architectures include:
- Llama – 3/3.1/3.2 (1B, 3B, 8B variants, including abliterated/uncensored)
- Qwen 2.5 – 0.5B, 1.5B, 3B, 7B Instruct
- Qwen 3 – 0.6B, 1.7B, 4B, 8B, 14B, 32B (including thinking/coder/abliterated variants, 30B MoE models)
- Phi-3 – Mini, Medium (4K context)
- Gemma – 1.1 (2B) (support for Gemma 2 and 3 coming later)
- SmolLM 2 – 135M, 360M, 1.7B
- SmolLM 3 – 3B
- Mixtral – 8x7B Instruct
- EuroMoE – 2.6B (0.6B active)
- SimpleChat – 4B, 14B
- DeepSeek – R1 variants
- TinyLlama – 1.1B Chat
French
Des LLM en Pascal en CPU, GPU planifié